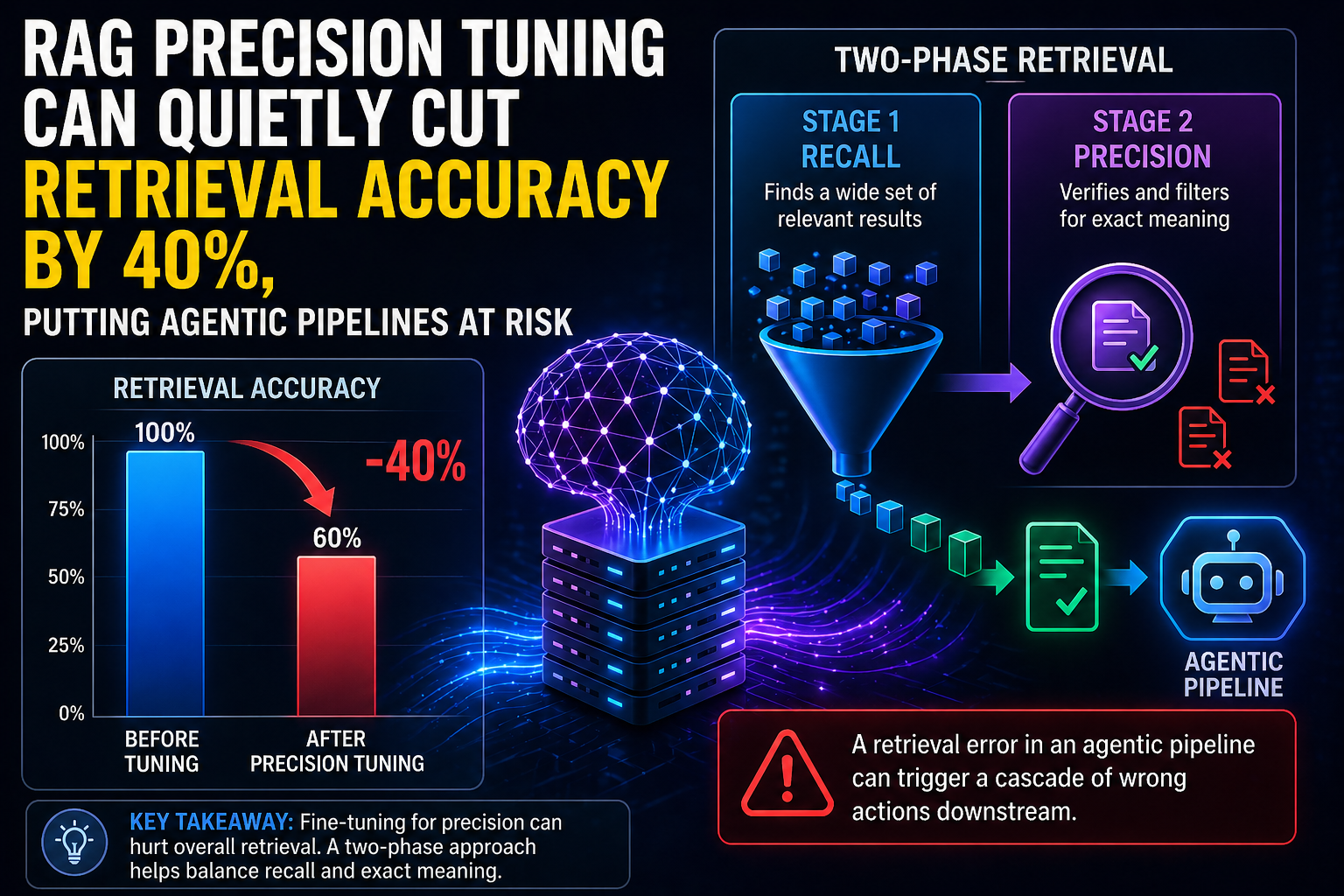
New research from Redis has revealed a serious issue in AI systems: trying to improve precision in RAG (Retrieval-Augmented Generation) models can actually reduce their overall accuracy.
Many companies fine-tune embedding models so they can better understand small differences in sentences. For example, “the dog bit the man” and “the man bit the dog” look similar but mean completely different things. This ability is called compositional sensitivity.
But here’s the problem: when models are trained to catch these differences, they lose their ability to retrieve correct information across broader topics. The research found performance drops of 8–9% in smaller models and up to 40% in mid-sized models already being used in real systems.
This becomes even more dangerous in advanced AI systems (agent-based pipelines). One small retrieval mistake can lead to a chain reaction of wrong decisions and outputs.
The reason behind this is how embedding models work. They compress sentences into points in a mathematical space. Similar-looking sentences often end up very close — even if their meanings are opposite. When you train the model to separate such sentences, it uses up space that was originally helping it find relevant information more broadly.
The study also showed that common solutions don’t fully fix the issue:
- Hybrid search (keywords + embeddings) fails because both sentences use the same words
- Reranking methods improve scores but miss meaning differences
- Cross-encoders are accurate but too slow and expensive
- Memory-based systems still depend on retrieval, so the problem remains
The recommended solution:
Instead of relying on a single system, use a two-stage approach:
- Stage One (Recall): Quickly fetch a wide set of relevant results using embeddings
- Stage Two (Precision): Use a smaller, smarter model to carefully check meaning and remove wrong matches
This approach performed best in catching errors that other systems missed, though it does add some delay (latency).
What it means for companies:
RAG is still useful and widely used, but it’s not perfect. Businesses need to understand that improving one area (precision) can harm another (retrieval quality). For high-risk fields like legal or finance, adding a second verification step is becoming necessary.


